Jadi aku memutuskan untuk mendokumentasilkan perjalananku dalam memulai Data Science Journey ini. Memang, aku sudah belajar Data Science dari sekitar 2 bulan yang lalu, namun aku merasa bahwa belajarku kurang efektif dan aku merasa bahwa otakku masih lemot untuk memproses beberapa hal.
Oleh karena itu, aku akan mendokumentasi perjalananku. Kata James Clear di blog nya, salah satu cara untuk stay in track adalah dengan mempublikasikan progress yang kita jalani. Dengan melakukannya, kita bisa semakin terdorong karena ada kemungkinan kita merasa malu apabila tidak mem-posting progress kita, jadi ini lah yang akan aku lakukan!
Aku akan memberi tahu apa saja yang sudah aku pelajari selama 2 bulan sebelumnya di postingan yang lain.
Sebelum memulai, aku akan memberi tahu bahwa untuk minggu ini fokus-ku adalah di STATISTIKA UNTUK DATA SCIENCE.
Buku yang aku gunakan adalah Practical Statistics for Data Scientiest by Peter Bruce & Andrew Bruce.
Beberapa hal yang aku pelajari hari ini :
- Weighted Mean & Trimmed Mean
- Median & Weighted Median
- Mean Absolute Deviation vs Standard Deviation
- Skewness and Kurtosis
- Boxplot
- Central Limit Theorem
- Histogram vs Bar Chart
Jadi, apa saja hal baru yang aku pelajari hari ini?
- Weighted Mean & Trimmed Mean
Rasanya semua orang pasti sudah mengetahui apa itu mean/ average/ rata-rata, yaitu penjumlahan dari semua variabel di sebuah data dibagi dengan jumlah variabel yang ada.
Tapi, apa itu weighted mean dan trimmed mean??
Kita mulai dari latar belakangnya terlebih dahulu. Jika ada mean biasa, untuk apa kita menggunakan weighted mean dan trimmed mean?
Jadi, weighted mean dan trimmed mean ini akan sangat berguna di Data Science apabila kita memiliki data yang ekstrem (atau biasa disebut outliers).
Sebagai contoh : Data Nilai Ujian Matematika Siswa adalah sebagai berikut {20, 70, 70, 70, 75, 100}.
Berapakah rata-ratanya?


Bisa dilihat bahwa hasil rata-rata dari Nilai Ujian Matematika Siswa adalah 81. Tapi, apakah hasil ini merepresentasikan data tersebut? Ya, tapi kurang akurat.
Hal ini disebabkan karena ada nya data ekstrem atau outliers di dalam data tersebut, yaitu nilai 20 dan 100. Trimmed Mean dan Weighted Mean digunakan untuk mengatasi kejadian yang seperti ini.
Trimmed Mean akan memangkas data yang ada agar hasil rata-rata lebih merepresentasikan data yang ada. Contohnya di dalam Data Ujian Matematika, outliers adalah nilai 20 dan 100. Dengan menggunakan Trimmed Mean, kita akan memangkas kedua nilai tersebut, kemudian menghitung rata-rata nya. Di kebanyakan kasus dalam Data Science, biasanya kita akan memangkas sekitar 5-10% dari data yang ada karena biasanya outliers terdapat di dalam 5-10% tersebut.

Untuk kesempatan ini, memang datanya sangat kecil dan rasanya apabila outliers tersebut dihilangkan, tidak akan memberikan perubahan yang banyak. Namun, ketika kita dihadapi oleh Data yang melimpah, hal ini akan sangat berguna.
Weighted Mean juga memiliki fungsi yang sama dengan Trimmed Mean, yaitu mengatasi outliers dengan mengkalikan weight dengan setiap variabel/ observation dalam data, kemudian menjumlahkannya.
Apa maksud dari weight? Dalam hal ini, weight adalah variabel pengali yang bisa berupa bagian dari data tersebut atau probabilitas data tersebut muncul/terjadi.
Contohnya, dalam kasus ini angka 70 muncul sebanyak 3 kali, oleh karena itu weight = 3/6 dimana 6 adalah jumlah dari data yang ada.
Dengan menggunakan weighted mean ini, kita akan mendapatkan mean yang lebih merepresentasikan data, dimana karena outliers berupa nilai 20 dan 100 hanya muncul sebanyak 1 kali, jadi weightnya hanya sebesar 1/6 dan ketika dijumlahkan nantinya nilai yang paling banyak terdapat di dalam data akan lebih dominan.


Weighted mean ini biasanya digunakan dalam menghitung IP atau nilai, dimana persentase dari setiap variabel berbeda-beda, contohnya untuk tugas diberi persentase 25%, ujian diberi persentase 75%.
2. Median & Weighted Median
Sebenarnya, jika terdapat outliers di dalam data kita, kita dapat menggunakan median untuk merepresentasikan data kita. Median adalah data yang berada di tengah-tengah, dan karena itulah median tidak akan dipengaruhi oleh outliers yang letaknya di paling depan/belakang.
Jadi, sebenarnya untuk mengatasi outliers, kita bisa saja dong menggunakan median, dibandingkan Trimmed Mean dan Weighted Mean? Ya, benar sekali.
NAMUN!! Untuk mendapatkan median, kita harus mengurutkan data kita terlebih dahulu, yang dimana untuk melakukannya akan menghabiskan banyak tenaga (manusia maupun komputer nanti!).
Lah, Trimmed Mean bukannya harus mengurutkan juga?
Tidak juga. Kita bisa saja hanya mencari 10 nilai min dan max data tanpa harus mengurutkan seluruh data yang di dunia Data Science jumlahnya bisa jutaan!
Untuk Weighted Median, dari wikipedia, aku dapat menyimpulkan bahwa weighted median adalah data tengah dari suatu data berdasarkan data tengah weight. Jadi, apabila sebelumnya kita mengurutkan datanya, dalam weighted median, kita akan mengurutkan weightnya terlebih dahulu, kemudian menjumlahkannya. Steleah itu, kita akan mencari data tengah dari weight tersebut dan melihat data untuk weight tersebut.
3. Mean Absolute Deviation vs Standard Deviation
Kedua variabel ini sempat membuatku bingung, karena keduanya sama-sama adalah jarak antar setiap data dengan rata-rata keseluruhan data, namun bedanya Mean Absolute Deviation meng-absolut kan jarak tersebut, sedangkan Standard Deviation mem-pangkatkan data tersebut kemudian meng-akarkannya.
Kedua cara tersebut dilakukan agar jarak tidak bernilai ngeatif (karena apabila jarak negatif, jika dijumlahkan akan saling menghilangkan dengan data jarak lainnya).
Di beberapa kasus, kedua nilai ini akan memiliki nilai yang sama, namun itu semua tergantung dari data. Biasanya nilai standard deviation akan lebih besar dari mean absolute deviation karena nilainya dipangkatkan (walaupun setelahnya diakarkan). Kebanyakan Data Scientist lebih suka menggunakan Standard Deviasi karena akan mempermudah di perhitungan untuk ke depannya. Selain itu, standard deviasi lebih banyak dikaitkan dengan perhitungan/ nilai lainnya (seperti variance, coef of variance).
4. Skewness and Kurtosis
Untuk skewness dan kertosis, ini sebenarnya berhubungan dengan bagaimana bentuk distribusi dari data. Gampangnya skew memberi tahu kecenderungan posisi puncak (kanan/kiri), sedangkan kertosis memberi tahu kecenderungan tinggi puncak.

Tenang saja, besok aku akan belajar lebih banyak mengenai distribusi untuk lebih lengkapnya!
5. Boxplot
Boxplot merupakan tools visualisasi yang bagus jika kita ingin melihat persebaran data dan melihat apakah data memiliki outliers atau tidak. Dengan membuat boxplot, kita bisa melihat pembagian data dengan lebih mudah.
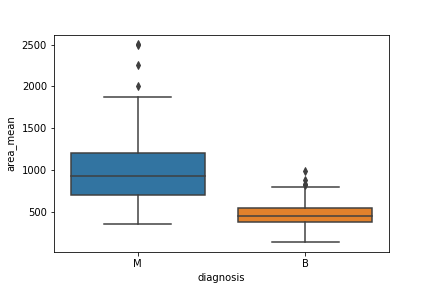
Jika dilihat dari gambar, titik titik bulat di atas box biru menandakan outliers yang terdapat di dalam data (biasanya outliers ini nilainya lebih besar dari 1.5 x data di 25%-75%). Garis di bawah titik titik tersebut menunjukkan nilai maksimum , sedangkan garis lurus di paling bawah menunjukkan nilai mininum. Garis lurus di box bagian atas menunjukkan data di 75% (75th percentile), sedangkan garis di bagian bawah box menunjukkan data di 25% (25th percentile). Garis lurus di tengah box menunjukkan median.
6. Central Limit Theorem
Topik ini menarik perhatianku ketika aku mencari ‘Data Science Interview Questions’. Nampaknya Central Limit Theorem ini banyak ditanyakan pada saat interview. Jadi sebenarnya apa itu Central Limit Theorem?
Simple nya adalah apabila kita ingin mengetahui rata-rata tinggi badan mahasiswa di Universitas X, namun populasi mahasiswa di Universitas X tersebut berjumlah 100.000 siswa. Tentu saja tidak mungkin kan kita mengukur tinggi badan setiap mahasiswa? Bagaimana cara mengatasinya?
Kita bisa menggunakan sampel, contohnya sampel dimana kita mengukur tinggi badan mahasiswa sebanyak 50 orang untuk setiap jurusan di Universitas X tersebut, dan merata-ratakan tinggi badan tersebut. Central Limit Theorem mengatakan bahwa distribusi dari rata-rata sampel dari setiap jurusan tersebut akan membentuk Normal/Gaussian Distribution, mau bagaimanapun bentuk distribusi dari populasi.
Populasi bisa saja berbentuk distribusi apapun (seperti gambar di bawah).
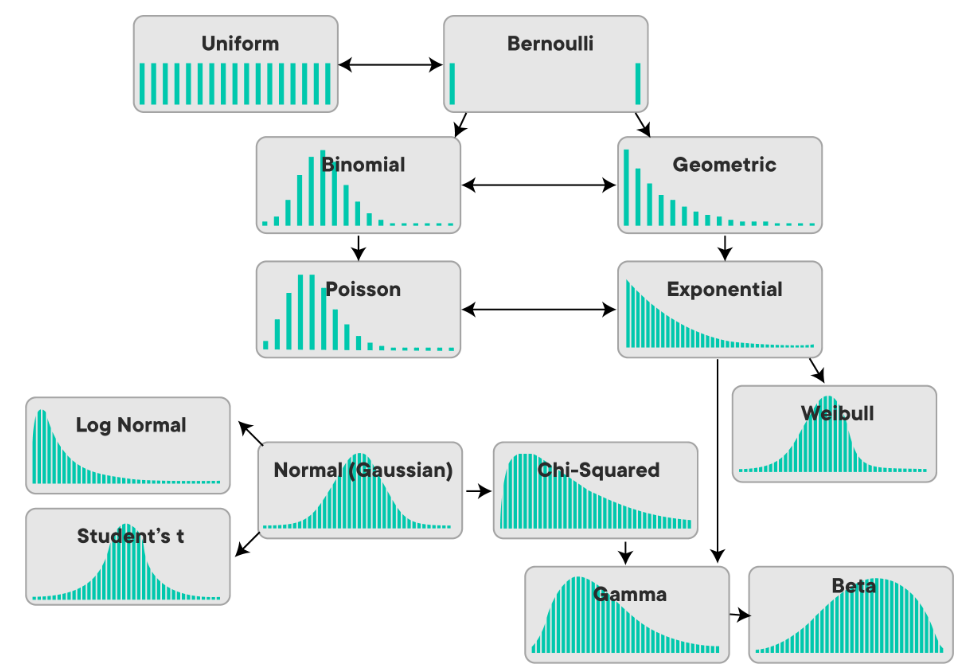
Namun, distribusi dari rata-rata sample dari populasi tersebut akan selalu membentuk Normal/Gaussian Distribution.
Teori ini akan sangat berguna dalam Data Science karena kita dapat mengasumsi bahwa distribusi mean dari sampling yang kita lakukan akan selalu membentuk normal distribution, dan distribution ini dapat kita gunakan untuk analisis lebih lanjut.
Namun, tetap saja ada beberapa ketentuan untuk teori ini, yaitu:
- Sampel harus diambil secara random
- Sampel tidak boleh berhubungan satu sama lain (independent)
Untuk lebih mengerti teori ini, kalian bisa melihat simulasi online Central Limit Theorm disini
7. Histogram vs Bar Chart
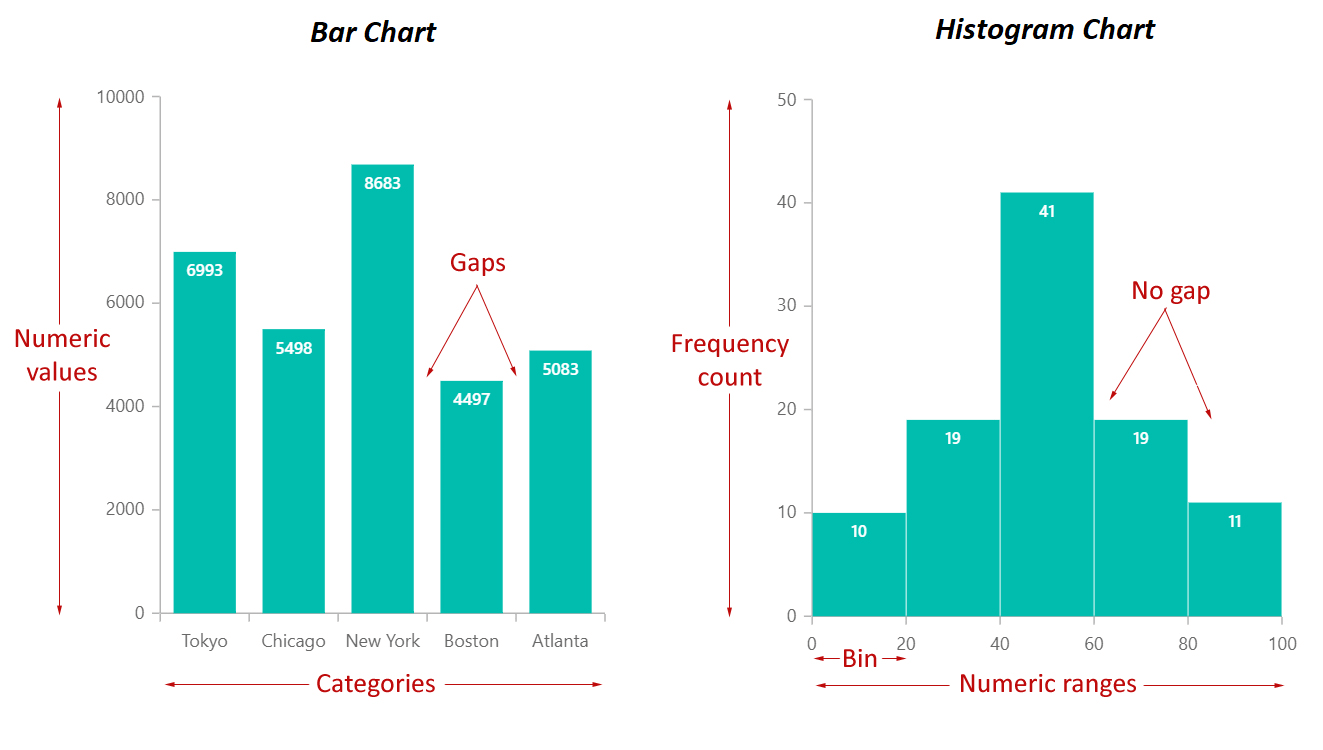
Apa sih bedanya histogram dan barchart? Sekilas nampaknya terlihat sama, seperti tiang-tiang panjang. Jika dilihat lebih lanjut lagi, bedanya hanya yang satu ada jarak, yang satu enggak. Jadi sebenarnya apa bedanya?
Walaupun terlihat mirip, namun kedua chart ini berbeda. Histogram memvisualisasikan continuous data, yaitu data yang memiliki banyak kemungkinan nilainya, seperti umur, tinggi badan, berat badan, harga barang, nilai ujian. Setiap tiang di histogram ini berhubungan satu sama lain. Contohnya data nilai ujian siswa. Angkanya bisa banyak sekali, mulai dari 20,45,43,70,71,82, dst.
Dalam histogram ini kita menggunakan range/bin untuk memvisualisasikan data tersebut. Kita bisa menggunakan range : 10-20, 20-30, 30-40, dst atau membagi data tersebut ke dalam beberapa bin. Katakanlah kita ingin membagi data tersebut menjadi 5 bin, contoh dalam kasus ini karena data memiliki range nilai 0-100, jika kita ingin membagi menjadi 5 bin, range tersebut akan dibagi menjadi 5 : 0-20, 21-40, 41-60, 61-80, 81-100.
Cara gampang menghafalnya adalah ingat saja histo dalam histogram mirip dengan kata history yang artinya riwayat, jadi bisa kita simulkan bahwa data tersebut berhubungan satu sama lain (ini konsep yang aku gunakan agar lebih mudah menghafal).
Untuk bar chart, tiang-tiang tersebut tidak ada hubungannya sama sekali! (itu lah penyebab tiang-tiang tersebut tidak nempel). Bar chart biasa digunakan untuk memvisualisasikan categorical data/ discrete data. Contohnya adalah data penduduk di setiap negara (Sumbu x menunjukkan nama kategori/ dalam hal ini nama negara dan sumbu y menunjukkan frekuensi/ jumlah penduduk)
Jadi, itu lah yang aku pelajari hari ini. Tidak terlalu banyak namun aku berharap bisa belajar setiap harinya walaupun dalam waktu yang singkat.
Catatan : Aku hanya menuliskan kesimpulan dari apa yang aku pelajari hari ini. Bisa saja terdapat kesalahan dalam tulisan ini Jika ada, mohon di koreksi! Karena aku juga sedang belajar 😀
Tulisan ini juga murni ditulis dengan kata-kata penulis sehingga terdapat kemungkinan bahasanya berlibet (mohon maklum belum di edit sama sekali).
